Harvard-Architektur
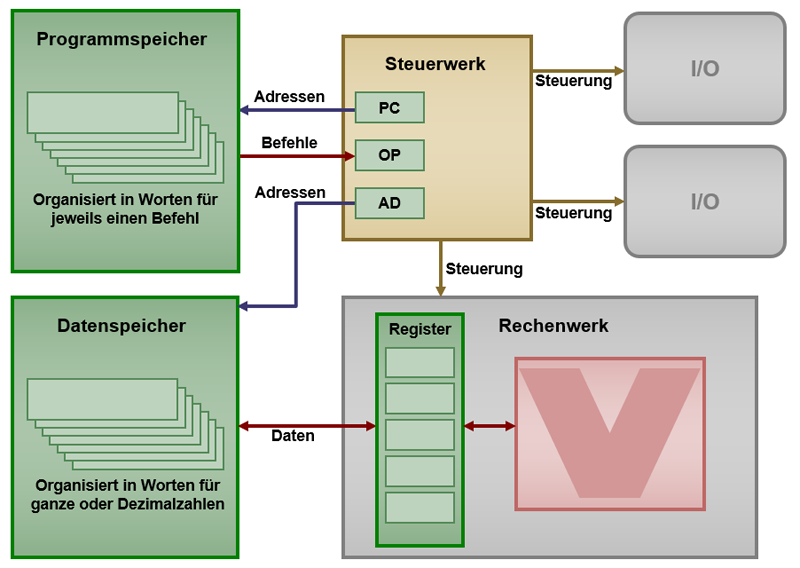
Die Harvard-Architektur geht auf den Computer Harvard Mark 1 zurück. Bei diesem gab es - wie auch bei den Zuse-Rechnern - einen separaten Speicher für das Programm und für die Daten.
Diese Architektur hat Vorteile, weil man die Wortbreite der beiden Speicher genau auf die jeweiligen Anforderungen zuschneiden kann. Bei einem Harvard-Rechner wird daher die Größe der Speicherworte separat angegeben ("z.B. Wortlänge: 20 Bit bei Befehlen und 4 Bit bei Daten"). Man kann auch verschiedene Speichertechnologien verwenden, beispielsweise Festspeicher für das Programm und Schreib-Lese-Speicher für die Daten. Befehle und Daten laufen in einem Harvard-Computer auf getrennten Datenpfaden und kommen sich so nicht in die Quere. Das bringt Performance-Vorteile.
Viele frühe Computer waren nach der Harvard-Architektur aufgebaut. So auch beispielsweise die meisten Systeme der mittleren Datentechnik. Der Kunde bestellte seinen Computer meist mit einem relativ kleinen Kernspeicher von teils nur wenigen Hundert Byte Kapazität. Betriebssystem und Anwendungsprogramm waren auf einem unveränderlichen Festspeicher "gefädelt". Meist gab es noch einen weiteren Speicher, der das Mikroprogramm ("Betriebsprogramm") des Steuerwerks enthielt. Für die Softwareentwicklung konnte man Teile des Festspeichers durch Kernspeicher ("Lebendspeicher") ersetzen, so dass man das Programm ändern und ausprobieren konnte. Im Laufe der Zeit gab es immer häufiger auch Computer mit Universalspeicher, der wahlweise Programme oder Daten aufnehmen konnte. Dies weichte das Harvard-Prinzip jedoch auf.
Im Laufe der Zeit setzte sich die Von-Neumann-Architektur (siehe folgendes Kapitel) zunehmend durch. Sie war einfacher zu implementieren, flexibler und brachte bei der Programmierung einige Vorteile mit sich.
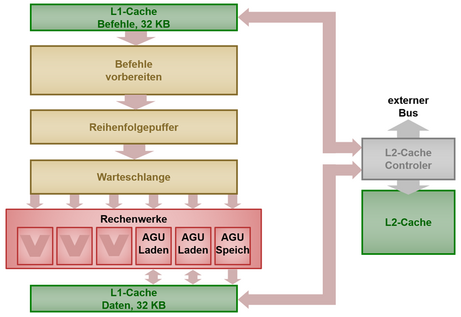
Trotzdem ist die Harvard-Architektur nicht ausgestorben. Man trifft sie bei sehr einfachen Steuerungscomputern immer noch an. Außerdem fand man auch bei modernen PC-Prozessoren zu einer modifizierten Harvard-Architektur zurück. Im Prozessor gibt es für Programmcode und Daten getrennte Zwischenspeicher (L1-Cache genannt). Dies beschleunigt die Zugriffe erheblich, weil Befehls- und Datencache getrennte Datenpfade haben. Nur wenn Daten aus einem nachgelagerten Cache oder dem Arbeitsspeicher geholt werden müssen, läuft das über den Von-Neumann-typischen gemeinsamen Datenbus.